FXWizard
Гуру форума
Ральф Винс. Математика управления капиталом
ВВЕДЕНИЕ
Обзор книги
В первом предложении пролога книги «Формулы управления портфелем», предыс- тории этой книги, я написал, что она посвящена математическим инструментам. Эта книга — о механизмах.
Мы возьмем инструменты и построим более усовершенствованные, более мощные инструменты — механизмы, где целое больше, чем сумма частей, и попытаемся понять устройство этих механизмов, иначе они были бы просто «черными ящиками». При этом мы воздержимся от детального рассмотрения всех так или иначе связанных тем (что сделало бы эту книгу невозможной). Например, рассуждение о том, как построить реактивный двигатель, может быть довольно подробным без необходимости преподавать вам химию, чтобы знать, как работает реактивное топливо. То же можно сказать и об этой книге, которая полностью полагается на многие области, особенно статистику, и затрагивает вычислитель- ные методы. Я не пытаюсь преподавать математику, кроме необходимого для по- нимания текста. Однако я попытался написать книгу таким образом, что если вы знаете вычислительные методы (или статистику), то для вас она будет полностью понятна, а если вы не знаете эти дисциплины, то будет небольшая, если будет во- обще, потеря смысла, и вы все еще сможете использовать и понимать (в большей части) материал, раскрываемый в книге, без ощутимых потерь.
Время от времени в статистике используются определенные математические функции. Эти функции, например, гамма-функции и неполные гамма-функции, а также бета и неполные бета-функции, часто называются функциями математи- ческой физики и находятся за границами рассматриваемого материала. Раскрытие их до глубины находится вне обзора данной книги, и даже далеко от ее направле- ния. Помните, что эта книга об управлении счетами трейдеров, а не математичес- кая физика. Для тех, кто действительно хочет знать «химию реактивного топлива», я предлагаю книгу «Числовые рецепты» (Numerical Recipes), на которую есть ссылка в разделе рекомендованной литературы. Я попытался осветить материал настолько глубоко, насколько возможно учитывая, что вы не обязательно должны знать вычислительные методы или функции математической физики, чтобы быть хорошим трейдером или управляющим деньгами. Мое мнение таково: между умом и зарабатыванием денег на рынках нет прямой зависимости. Этим я не хочу сказать, что чем глупее вы являетесь, тем выше ваши шансы на успех в торговле. Я имею в виду, что один только ум является очень небольшой составляющей в уравнении, которое определяет хорошего трейлера. В отношении того, что же по моему мнению делает хорошего трейлера, могу сказать, что это ментальная прочность и дисциплина, которые намного перевешивают ум. Каждый успешный трейдер, которого я когда-либо встречал или о котором слышал, имел, по крайней мере. один опыт огромного убытка. Общим знаменателем, характеристикой, которая отделяет хорошего трейдера от остальных, является то, что хороший трейдер поднимает телефонную трубку и размещает ордер, когда ситуация находится в самом мрачном состоянии. Это требует от человека намного больше,
чем может дать знание вычислительных методов или статистики. Одним словом, я написал эту книгу, чтобы ее использовали трейдеры на реальных рынках. Я не академик. Мой интерес в реальном использовании, и он превыше академической высоты. Более того, я попытался предоставить больше базовой информации, чем требуется для книги, в надежде, что читатель будет исследовать концепции глубже, чем это сделал я. Меня всегда интриговала архитектура музыки, теория музыки. Мне нравится читать и узнавать о ней, однако я не музыкант. Чтобы быть музыкантом, нужна определенная дисциплина, чего не может дать простое понимание основ музыкальной теории. То же можно сказать про торговлю. Управление деньгами может быть в корне здравой торговой программой, но простое понимание управления деньгами не сделает из вас успешного трейдера. Эта книга о музыкальной теории, а не инструкция игры на инструменте. Она не о победе над рынками, и вы не найдете в ней ни одного ценового графика. Эта книга посвящена математическим концепциям и делает важный шаг от теории к практике, но она не наделит вас способностью переносить эмоциональную боль, которую торговля неизбежно припасла для вас. Эта книга не является продолжением книги «Формулы управления портфелем». Наоборот, книга «Формулы управления портфелем» заложила основу для тем, раскрываемых здесь. Эта книга глубже и серьезнее предыдущей. Для тех, кто не читал книгу «Формулы управления портфелем», глава 1 раскроет основные ее концепции. Включение этих концепций делает книгу, которую вы держите в руках, независимой от моей предыдущей книги. Многие идеи, раскрытые здесь, уже применяются на практике профессиональными управляющими капиталом. Однако идеи, которые распространены среди профессиональных управляющих капиталом, обычно недоступны частным инвесторам. Так как здесь замешаны деньги, то все стараются держать в тайне методы управления портфелем. Поиск такой информации — это как попытка найти информацию об атомных бомбах. Я крайне признателен многим библиотекарям, которые помогли мне разобраться в бесчисленных лабиринтах профессиональных журналов и заполнить пробелы, чтобы создать эту книгу. Чтобы использовать инструменты, которые здесь описываются, не обязательно применять механическую объективную торговую систему. Другими словами, тот, кто, например, использует волны Эллиотта для принятия торговых решений, также может применять оптимальное f. Однако методы, описанные в этой книге, как и те, которые освещены в книге «Формулы управления портфелем», требуют, чтобы сумма ваших ставок была поло- жительным результатом. Другими словами, эти методы дадут вам многое, но они не сделают чуда. Грамотное управление деньгами не превратит ваши убытки в прибыли. Вы изначально должны иметь выигрышный подход.
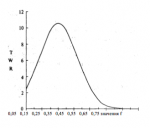
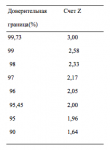
Большинство методов, рассматриваемых в этой книге, эффективны при дол- госрочных стратегиях. На протяжении всей книги вы будете встречать термин «асимптотический смысл», что означает возможный результат чего-либо, осуще- ствленного бесконечное число раз, когда вероятность приближается к определен- ности при увеличении количества попыток. Другими словами, что-то, в чем мы можем быть почти уверены с течением времени. Смысл этого выражения содер- жится в математическом термине «асимптота», которая является прямой и огра- ничивает кривую линию в том понимании, что расстояние между двигающейся точкой кривой и прямой линией приближается к нулю, когда точка удаляется на бесконечное расстояние от начала координат.
Торговля никогда не была легким занятием. Когда трейдеры изучают эти кон- цепции, то часто приобретают ложное чувство силы. Я говорю «ложное», так как складывается впечатление, будто что-либо, что очень трудно сделать, на самом деле очень легко, если понять механику процесса. Когда вы будете читать эту кни- гу, помните, что в ней нет ничего, что может сделать вас лучшим трейдером, ниче- го, что может улучшить ваш фактор времени входа на рынок и выхода с него, ни-
чего, что улучшит ваш торговый выбор. Эти трудные задачи так и останутся труд- ными, даже после того, как вы прочтете и поймете эту книгу.
После издания книги «Формулы управления портфелем» меня не раз спрашива- ли, почему я решился ее написать. Обычный аргумент против такого шага состоит в том, что рынок — это конкурентная арена, и когда вы пишете книгу, это анало- гично тому, что вы делитесь информацией со своими противниками.
Мало кто представляет, насколько обширны сегодня рынки. Да, рынки — это игра, где деньги переходят от одного участника к другому. Но в силу их огромного размера, вы, читатель, не являетесь моим соперником.
Чаще всего я сам и являюсь своим главным врагом. Это верно не только в от- ношении моей торговли на рынках, но и вообще в жизни. Другие трейдеры не представляют мне такой угрозы, какую представляю для себя я сам. Я не думаю, что одинок в этом, и полагаю, что большинство трейдеров согласятся со мной. В середине 1980-х годов, когда компьютер стал основным инструментом трейдеров, появилось большое количество торговых программ, которые открывали позицию по стоп-ордеру, и размещение этих стоп-ордеров часто зависело от текущей волатильности на данном рынке. Эти системы некоторое время работали прекрасно. Затем,* к концу десятилетия, такие виды систем почти перестали ис- пользовать. В лучшем случае они приносили только малую долю прибылей, по сравнению с несколькими годами ранее. Большинство трейдеров, применявших эти системы, впоследствии перестали их использовать, заявляя, что «раз все ими пользуются, то как они могут работать?» .
Большинство этих систем применяли на рынке фьючерсов на казначейские облигации. Давайте рассмотрим теперь размер рынка, лежащего в основе фьючерсного рынка. Когда цены на рынке спот и фьючерсном рынке расходятся (обычно не более чем на несколько тиков), в игру вступают арбитражеры, покупая менее дорогостоящий из двух инструментов и продавая более дорогостоящий. В результате расхождение между ценой спот-рынка и ценой фьючерсного рынка достаточно быстро исчезает. Разница между ценой на спот-рынке и фьючерсном рынке может действительно сильно измениться, только когда внешний шок (ка- кие-либо неожиданные события или новости) ведет цены к большему расхожде- нию, чем это бывает при обычном процессе арбитража. Такие разрывы происходят обычно в течение очень короткого времени и встречаются довольно редко. Арбитражеры зарабатывает на ценовых различиях, тем самым сглаживая их. В ре- зультате этого процесса, рынок фьючерсов казначейских облигаций внутренне привязан к огромному спот-рьшку казначейских обязательств. Фьючерсный рынок отражает, по крайней мере, до нескольких тиков то, что происходит на гигантском спот-рынке, который никогда не был ведомым системными трейдерами, скорее наоборот.
Вернемся теперь к нашему спору. Маловероятно, чтобы трейдеры на спот- рынке и на фьючерсном рынке начали торговать по одной системе в одно и то же время! Также маловероятно, чтобы участники спот-рынка решили вступить в сговор против тех, кто процветает на фьючерсном рынке. Тот факт, что многие фьючерсные трейдеры торговали с помощью этих систем, не является действи- тельной причиной того, что системы перестали работать, поскольку это также означало бы, что крупный участник на любом небольшом по объему рынке был бы обречен на неудачу. Таким же образом глупо было бы полагать, что, как только выйдет в свет моя книга по концепциям управления счетом, все сливки с рынка будут моментально сняты.
Победа над рынком требует больше, чем понимание концепций управления деньгами. Она требует дисциплины, чтобы вынести эмоциональную боль, которую 19 из 20 людей не могут вынести. Этому вы не научитесь ни с помощью этой, ни с помощью любой другой книги. Тот, кто заявляет, что он заинтригован «интеллектуальным вызовом рынков», — не трейдер. Рынки так же интеллекту-
альны, как и кулачный бой. Лучший совет, который я могу дать, — это всегда закрывать свой подбородок и челюсть. Проиграете вы или выиграете, все равно будут значительные удары. В действительности на рынках мало что относится к интеллектуальному вызову; в конечном счете, торговля — это упражнение на самообладание и выносливость. Эта книга пытается детально объяснить стратегию кулачного боя, и ее следует использовать только тому, кто уже обладает не- обходимой ментальной прочностью.
ВВЕДЕНИЕ
Обзор книги
В первом предложении пролога книги «Формулы управления портфелем», предыс- тории этой книги, я написал, что она посвящена математическим инструментам. Эта книга — о механизмах.
Мы возьмем инструменты и построим более усовершенствованные, более мощные инструменты — механизмы, где целое больше, чем сумма частей, и попытаемся понять устройство этих механизмов, иначе они были бы просто «черными ящиками». При этом мы воздержимся от детального рассмотрения всех так или иначе связанных тем (что сделало бы эту книгу невозможной). Например, рассуждение о том, как построить реактивный двигатель, может быть довольно подробным без необходимости преподавать вам химию, чтобы знать, как работает реактивное топливо. То же можно сказать и об этой книге, которая полностью полагается на многие области, особенно статистику, и затрагивает вычислитель- ные методы. Я не пытаюсь преподавать математику, кроме необходимого для по- нимания текста. Однако я попытался написать книгу таким образом, что если вы знаете вычислительные методы (или статистику), то для вас она будет полностью понятна, а если вы не знаете эти дисциплины, то будет небольшая, если будет во- обще, потеря смысла, и вы все еще сможете использовать и понимать (в большей части) материал, раскрываемый в книге, без ощутимых потерь.
Время от времени в статистике используются определенные математические функции. Эти функции, например, гамма-функции и неполные гамма-функции, а также бета и неполные бета-функции, часто называются функциями математи- ческой физики и находятся за границами рассматриваемого материала. Раскрытие их до глубины находится вне обзора данной книги, и даже далеко от ее направле- ния. Помните, что эта книга об управлении счетами трейдеров, а не математичес- кая физика. Для тех, кто действительно хочет знать «химию реактивного топлива», я предлагаю книгу «Числовые рецепты» (Numerical Recipes), на которую есть ссылка в разделе рекомендованной литературы. Я попытался осветить материал настолько глубоко, насколько возможно учитывая, что вы не обязательно должны знать вычислительные методы или функции математической физики, чтобы быть хорошим трейдером или управляющим деньгами. Мое мнение таково: между умом и зарабатыванием денег на рынках нет прямой зависимости. Этим я не хочу сказать, что чем глупее вы являетесь, тем выше ваши шансы на успех в торговле. Я имею в виду, что один только ум является очень небольшой составляющей в уравнении, которое определяет хорошего трейлера. В отношении того, что же по моему мнению делает хорошего трейлера, могу сказать, что это ментальная прочность и дисциплина, которые намного перевешивают ум. Каждый успешный трейдер, которого я когда-либо встречал или о котором слышал, имел, по крайней мере. один опыт огромного убытка. Общим знаменателем, характеристикой, которая отделяет хорошего трейдера от остальных, является то, что хороший трейдер поднимает телефонную трубку и размещает ордер, когда ситуация находится в самом мрачном состоянии. Это требует от человека намного больше,
чем может дать знание вычислительных методов или статистики. Одним словом, я написал эту книгу, чтобы ее использовали трейдеры на реальных рынках. Я не академик. Мой интерес в реальном использовании, и он превыше академической высоты. Более того, я попытался предоставить больше базовой информации, чем требуется для книги, в надежде, что читатель будет исследовать концепции глубже, чем это сделал я. Меня всегда интриговала архитектура музыки, теория музыки. Мне нравится читать и узнавать о ней, однако я не музыкант. Чтобы быть музыкантом, нужна определенная дисциплина, чего не может дать простое понимание основ музыкальной теории. То же можно сказать про торговлю. Управление деньгами может быть в корне здравой торговой программой, но простое понимание управления деньгами не сделает из вас успешного трейдера. Эта книга о музыкальной теории, а не инструкция игры на инструменте. Она не о победе над рынками, и вы не найдете в ней ни одного ценового графика. Эта книга посвящена математическим концепциям и делает важный шаг от теории к практике, но она не наделит вас способностью переносить эмоциональную боль, которую торговля неизбежно припасла для вас. Эта книга не является продолжением книги «Формулы управления портфелем». Наоборот, книга «Формулы управления портфелем» заложила основу для тем, раскрываемых здесь. Эта книга глубже и серьезнее предыдущей. Для тех, кто не читал книгу «Формулы управления портфелем», глава 1 раскроет основные ее концепции. Включение этих концепций делает книгу, которую вы держите в руках, независимой от моей предыдущей книги. Многие идеи, раскрытые здесь, уже применяются на практике профессиональными управляющими капиталом. Однако идеи, которые распространены среди профессиональных управляющих капиталом, обычно недоступны частным инвесторам. Так как здесь замешаны деньги, то все стараются держать в тайне методы управления портфелем. Поиск такой информации — это как попытка найти информацию об атомных бомбах. Я крайне признателен многим библиотекарям, которые помогли мне разобраться в бесчисленных лабиринтах профессиональных журналов и заполнить пробелы, чтобы создать эту книгу. Чтобы использовать инструменты, которые здесь описываются, не обязательно применять механическую объективную торговую систему. Другими словами, тот, кто, например, использует волны Эллиотта для принятия торговых решений, также может применять оптимальное f. Однако методы, описанные в этой книге, как и те, которые освещены в книге «Формулы управления портфелем», требуют, чтобы сумма ваших ставок была поло- жительным результатом. Другими словами, эти методы дадут вам многое, но они не сделают чуда. Грамотное управление деньгами не превратит ваши убытки в прибыли. Вы изначально должны иметь выигрышный подход.
Большинство методов, рассматриваемых в этой книге, эффективны при дол- госрочных стратегиях. На протяжении всей книги вы будете встречать термин «асимптотический смысл», что означает возможный результат чего-либо, осуще- ствленного бесконечное число раз, когда вероятность приближается к определен- ности при увеличении количества попыток. Другими словами, что-то, в чем мы можем быть почти уверены с течением времени. Смысл этого выражения содер- жится в математическом термине «асимптота», которая является прямой и огра- ничивает кривую линию в том понимании, что расстояние между двигающейся точкой кривой и прямой линией приближается к нулю, когда точка удаляется на бесконечное расстояние от начала координат.
Торговля никогда не была легким занятием. Когда трейдеры изучают эти кон- цепции, то часто приобретают ложное чувство силы. Я говорю «ложное», так как складывается впечатление, будто что-либо, что очень трудно сделать, на самом деле очень легко, если понять механику процесса. Когда вы будете читать эту кни- гу, помните, что в ней нет ничего, что может сделать вас лучшим трейдером, ниче- го, что может улучшить ваш фактор времени входа на рынок и выхода с него, ни-
чего, что улучшит ваш торговый выбор. Эти трудные задачи так и останутся труд- ными, даже после того, как вы прочтете и поймете эту книгу.
После издания книги «Формулы управления портфелем» меня не раз спрашива- ли, почему я решился ее написать. Обычный аргумент против такого шага состоит в том, что рынок — это конкурентная арена, и когда вы пишете книгу, это анало- гично тому, что вы делитесь информацией со своими противниками.
Мало кто представляет, насколько обширны сегодня рынки. Да, рынки — это игра, где деньги переходят от одного участника к другому. Но в силу их огромного размера, вы, читатель, не являетесь моим соперником.
Чаще всего я сам и являюсь своим главным врагом. Это верно не только в от- ношении моей торговли на рынках, но и вообще в жизни. Другие трейдеры не представляют мне такой угрозы, какую представляю для себя я сам. Я не думаю, что одинок в этом, и полагаю, что большинство трейдеров согласятся со мной. В середине 1980-х годов, когда компьютер стал основным инструментом трейдеров, появилось большое количество торговых программ, которые открывали позицию по стоп-ордеру, и размещение этих стоп-ордеров часто зависело от текущей волатильности на данном рынке. Эти системы некоторое время работали прекрасно. Затем,* к концу десятилетия, такие виды систем почти перестали ис- пользовать. В лучшем случае они приносили только малую долю прибылей, по сравнению с несколькими годами ранее. Большинство трейдеров, применявших эти системы, впоследствии перестали их использовать, заявляя, что «раз все ими пользуются, то как они могут работать?» .
Большинство этих систем применяли на рынке фьючерсов на казначейские облигации. Давайте рассмотрим теперь размер рынка, лежащего в основе фьючерсного рынка. Когда цены на рынке спот и фьючерсном рынке расходятся (обычно не более чем на несколько тиков), в игру вступают арбитражеры, покупая менее дорогостоящий из двух инструментов и продавая более дорогостоящий. В результате расхождение между ценой спот-рынка и ценой фьючерсного рынка достаточно быстро исчезает. Разница между ценой на спот-рынке и фьючерсном рынке может действительно сильно измениться, только когда внешний шок (ка- кие-либо неожиданные события или новости) ведет цены к большему расхожде- нию, чем это бывает при обычном процессе арбитража. Такие разрывы происходят обычно в течение очень короткого времени и встречаются довольно редко. Арбитражеры зарабатывает на ценовых различиях, тем самым сглаживая их. В ре- зультате этого процесса, рынок фьючерсов казначейских облигаций внутренне привязан к огромному спот-рьшку казначейских обязательств. Фьючерсный рынок отражает, по крайней мере, до нескольких тиков то, что происходит на гигантском спот-рынке, который никогда не был ведомым системными трейдерами, скорее наоборот.
Вернемся теперь к нашему спору. Маловероятно, чтобы трейдеры на спот- рынке и на фьючерсном рынке начали торговать по одной системе в одно и то же время! Также маловероятно, чтобы участники спот-рынка решили вступить в сговор против тех, кто процветает на фьючерсном рынке. Тот факт, что многие фьючерсные трейдеры торговали с помощью этих систем, не является действи- тельной причиной того, что системы перестали работать, поскольку это также означало бы, что крупный участник на любом небольшом по объему рынке был бы обречен на неудачу. Таким же образом глупо было бы полагать, что, как только выйдет в свет моя книга по концепциям управления счетом, все сливки с рынка будут моментально сняты.
Победа над рынком требует больше, чем понимание концепций управления деньгами. Она требует дисциплины, чтобы вынести эмоциональную боль, которую 19 из 20 людей не могут вынести. Этому вы не научитесь ни с помощью этой, ни с помощью любой другой книги. Тот, кто заявляет, что он заинтригован «интеллектуальным вызовом рынков», — не трейдер. Рынки так же интеллекту-
альны, как и кулачный бой. Лучший совет, который я могу дать, — это всегда закрывать свой подбородок и челюсть. Проиграете вы или выиграете, все равно будут значительные удары. В действительности на рынках мало что относится к интеллектуальному вызову; в конечном счете, торговля — это упражнение на самообладание и выносливость. Эта книга пытается детально объяснить стратегию кулачного боя, и ее следует использовать только тому, кто уже обладает не- обходимой ментальной прочностью.
")